




TSDB


A dataset hub for open time-series benchmarks.
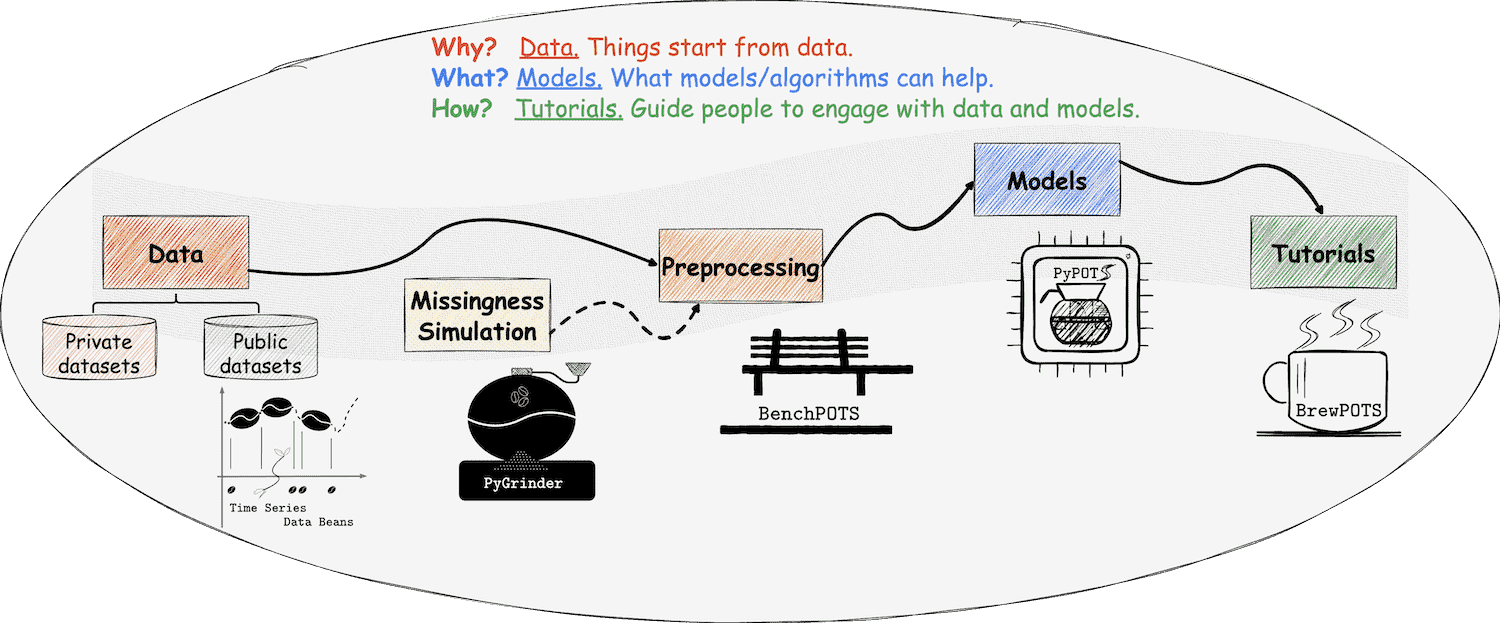
In the PyPOTS universe, datasets are coffee beans, and POTS datasets are beans with meaningful missing parts. TSDB (Time Series Data Beans) makes these resources easy to access through a unified loading interface for a wide range of public datasets. It currently supports 173 open-source datasets, helping you start experiments quickly and reproducibly.
PyGrinder


A toolkit for generating realistic missingness in time series.
PyGrinder is built to simulate real-world incompleteness by "grinding" full datasets into partially-observed ones. It supports all major missingness mechanisms based on Rubin's framework: MCAR, MAR, and MNAR. With simple APIs, you can inject synthetic missing values and control missing patterns for robust model evaluation.
BenchPOTS


A unified benchmarking suite for machine learning on POTS.
BenchPOTS provides standardized preprocessing and evaluation pipelines for partially-observed time-series tasks. It helps researchers and engineers compare methods fairly across datasets, settings, and task types. With consistent protocols, benchmarking becomes more transparent, reproducible, and decision-friendly.
PyPOTS


The core toolbox for modeling partially-observed time series.
Once the beans are prepared, PyPOTS is the coffee pot that brews them into high-value analysis results. PyPOTS integrates dozens of algorithms with unified APIs for end-to-end imputation, forecasting, classification, clustering, and anomaly detection. Since 2022, it has been widely adopted in scientific and industrial projects, with growing citations and references. Here is an incomplete list.
BrewPOTS

The tutorial repository for practical PyPOTS workflows.
With the beans, grinder, benchmark, and pot in place, BrewPOTS shows you how to put everything together.
It hosts practical tutorials, examples, and walkthroughs so you can move from setup to results efficiently.
Visit BrewPOTS to learn how to build complete POTS workflows in real projects.
☕️ Welcome to the PyPOTS universe.
